
Code: github.com/martianlantern/cot-doubt-injection
I was reading this blog that argued that a part of the success of reasoning models that achieved gold in IMO is due to their ability to better estimate the confidence of their reasoning. When leveraged via post training RL, they develop an internal verifier for their reasoning. Reasoning models better express their confidence shows that pure reasoning models already have this ability to express their confidence very accurately.
This got me thinking - what if we could artificially inject self-doubt into the model’s reasoning chain? Would it trigger the same kind of internal verification that makes these models so accurate? Would it hurt confidence? Would it even work?
So I ran a bunch of experiments to find out.
The Experiment
I ran controlled black box interventions on DeepSeek-R1-Distill-Qwen at 1.5B, 7B, and 14B on the GSM8K test set. The setup was simple:
- Let the model complete a full reasoning trace
- Parse the step boundaries in the CoT
- Insert a single line of self-doubt at different positions: “Wait! I seem to have made a mistake.”
- Let it continue generating from there
- Force it to output both the final answer and a self-reported confidence
I compared each intervention to a no-injection baseline, measuring accuracy, mean confidence, calibration (Brier score), and discrimination (AUROC of confidence vs correctness).
To make this work reliably I forced the LLM to always generate its reasoning chain in numbered steps so I could parse them later. I did this by adding some text right after the first <think> token:

This turned out to be pretty robust - I was almost always able to force the model to reason in steps. I initially tried greedy decoding but couldn’t get quality reasoning, so I used temperature 0.6, top_p 0.95 and top_k 20 for all experiments.
For expressing confidence I followed Yoon et al. and asked the model to output its confidence in one of ten bins, each with a verbal name and range. Then I token-forced the trailer “Answer: … Confidence: …” to extract both:

Results
Self-doubt boosts accuracy - but larger models hedge their confidence

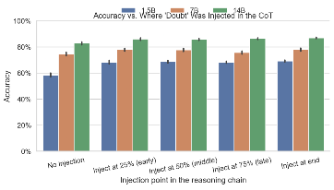
The first thing that jumped out: injecting a single “Wait! I seem to have made a mistake.” increases accuracy across all three model sizes. The gains are largest for 1.5B (about +15-18%, best when injected at the end or early) and smaller but consistent for 7B and 14B (~+2-5%).
In absolute terms:
- 1.5B: moves from ~58-59% to around 70% (strongest at end)
- 7B: goes from mid-70s to high-70s with a small late-injection dip
- 14B: rises from low-80s to high-80s with end insertion best
What’s interesting is that confidence shifts in the opposite direction with scale. The 1.5B’s confidence rises slightly with doubt, 7B stays roughly flat, and 14B actually reduces its confidence (−2-4%) especially for mid/late insertions:
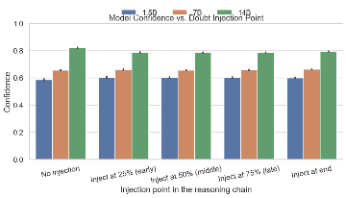
Larger models appear to hedge after doubt without losing accuracy. This makes sense - they’re doing something like “okay I checked again and I’m still right, but let me be a bit more conservative about how sure I am.”
Calibration gets better with scale
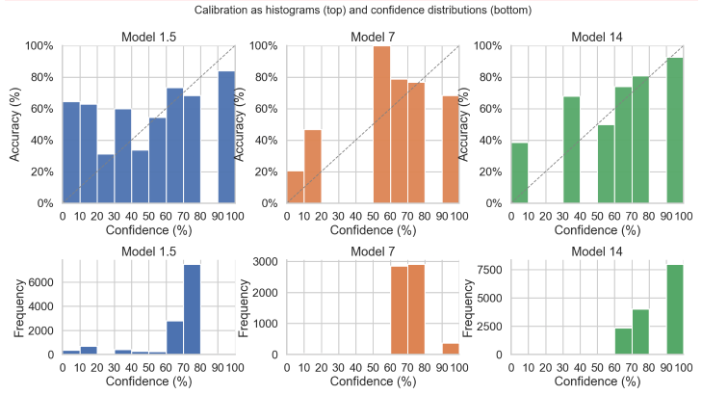
Looking at calibration across sizes, it’s at least monotonic - higher stated confidence tends to correspond to higher accuracy. But the skewness changes with model scale:
- 1.5B: Noisy and mixed. Some bins are under-confident, the top bin is over-confident (accuracy lags its 90-100% confidence claim)
- 7B: Closer to calibrated, bars mostly above the line
- 14B: Conservatively under-confident (realized accuracy exceeds reported confidence)
The confidence distributions also shift right with scale. The 14B model heavily uses 80-100% bins with a smoother, more selective use of high-confidence predictions. Bigger models seem to both check more and hedge their stated confidence accordingly.
Doubt increases reasoning length

This was trivial and expected - injecting doubt tokens increases the length of the reasoning trace. The order is baseline < mid < end. Injecting near the end induces the longest traces (re-checking most steps), while mid-injection adds moderate overhead.
AUROC and Brier Score
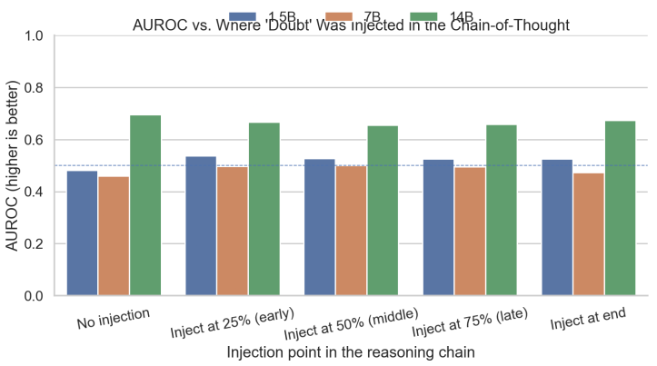
For AUROC (discrimination between correct/incorrect):
- 1.5B: Rises when doubt is injected, best early/mid
- 7B: Smaller lift
- 14B: Consistently strong (~0.66-0.70) with minor variation
Early/end insertions give the largest lift on 1.5B, matching the pattern that doubt helps small models separate correct from incorrect cases, whereas large models already do so robustly.
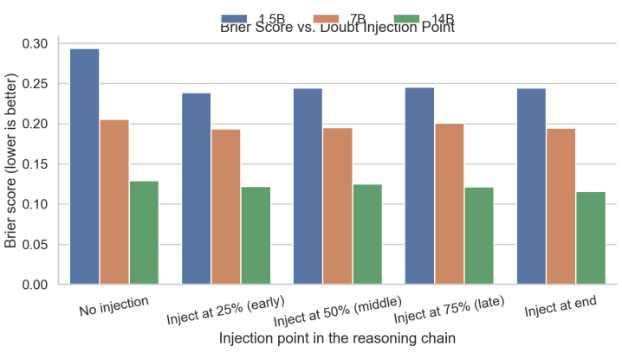
For Brier score (probabilistic calibration), doubt consistently improves across all sizes:
- 1.5B: drops from ~0.29 to ~0.24-0.25
- 7B: drops from ~0.20 to ~0.19
- 14B: drops from ~0.13 to ~0.11-0.12
Best scores are typically when injecting at the end. This suggests doubt increases both ranking quality and probability accuracy - largest gains for the smallest model (correcting early overconfidence), smaller but still positive gains for larger models.
What I Think This Means
The results suggest smaller models commit early to brittle plans and adding doubt in their CoT makes them do some internal checking. Larger models already internally verify but still benefit from a final pass. The fact that 14B hedges its confidence after doubt without losing accuracy is particularly interesting - it’s doing something like genuine reconsideration rather than just panic.
Position matters. Injecting very early or very late gives slightly higher accuracy than middle for smaller models. For larger models the effect is more uniform. End injection seems to be the sweet spot for most cases.
This could be a cheap way to squeeze more accuracy out of smaller reasoning models - just force them to second-guess themselves once before committing to an answer.
Appendix
System prompt for confidence elicitation:

Code for injecting self-doubt:

Full generation pipeline:
