
Deepseek.ai recently released DeepSeek OCR model. It has a lot of innovations in model architecture and dataset. But it also has a rather interesting section. They ablate on the number of text tokens that are being represented by a single image tokens. Turns out we can achieve 10 times compression while maintaining good precision.
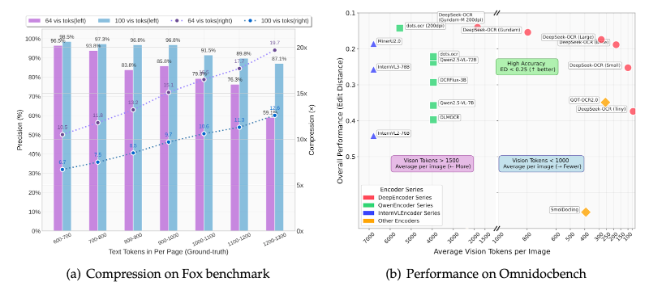
They show that each image token contains 10 text tokens worth of information. This means that the model’s internal representation for image tokens is much better than that of text tokens. This makes it even more feasible to feed images even if we have text inputs, render the text in an image and then feed that as input because we have more information compression, more context lengths and better efficiency.
If this holds at long contexts we can design better llm inference serving for long contexts, fitting orders of magnitude more content in the same window. Visual encoding trades off some precision in token alignment and fine grained reasoning. You lose some token-level controllability, models can’t easily quote or copy text from compressed visual input. But for reasoning tasks that depend on conceptual understanding rather than literal text reproduction, this could be a huge win.
It’s also worth thinking about what this implies for future architectures. If image tokens are inherently more efficient, the next generation of models might not distinguish as sharply between “vision” and “language.” They could operate on a unified latent space where both modalities are just different projections of the same compressed meaning manifold. This could emerge as a new scaling law for multimodal reasoning rather than only an OCR trick :)
References: