
I’ve been thinking about LLM routing lately and one idea that keeps coming back to me is using the model’s internal confidence signal to decide which model should answer a query. The intuition is simple: if a small model is confident about its answer, why bother calling the expensive one? And if it’s uncertain, escalate to something bigger. This could save a ton of compute if it works.
To test this I ran a quick experiment. I generated responses from 6 different models of the Qwen2.5 Series ranging from 0.5B to 32B parameters on GSM8K. For each response I extracted the log probabilities of the answer tokens to get an estimate of the model’s confidence. Then I measured Pass@1 accuracies to see how well each model actually performed.
| Model | Measured Pass@1 | Reported (4-shot) |
|---|---|---|
| Qwen2.5-0.5B-Instruct | 21.759 | — |
| Qwen2.5-1.5B-Instruct | 40.258 | 73.2 |
| Qwen2.5-3B-Instruct | 82.259 | 86.7 |
| Qwen2.5-7B-Instruct | 91.054 | 91.6 |
| Qwen2.5-14B-Instruct | 94.390 | 94.8 |
| Qwen2.5-32B-Instruct | 95.224 | 95.9 |
Reported metrics are taken from the Qwen2.5 Technical Report. The gap between my measured and reported numbers for smaller models is probably because I’m doing 0-shot while they did 4-shot, but that’s fine for this experiment.
The Confidence Signal Problem
Here’s the thing - for this routing idea to work, the confidence signal needs to actually mean something. Ideally we want the confidence histograms for correct answers to be clearly separated from incorrect ones. If there’s too much overlap, the router won’t be able to tell when to trust the model and when to escalate.
I tried a bunch of different ways to extract confidence from the log probs:
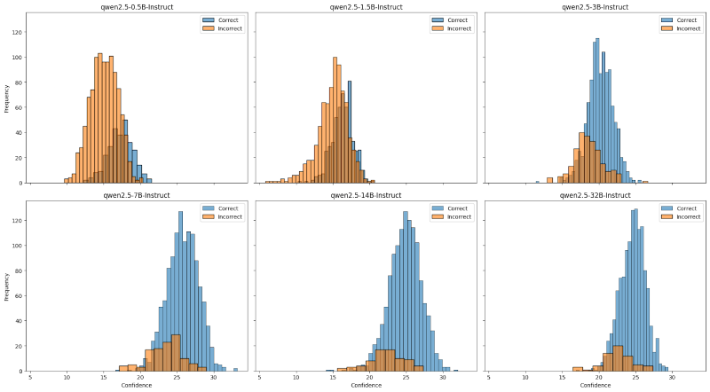
Average Trace Confidence
Just averaging the log probs across all tokens in the response. This is the most naive approach.
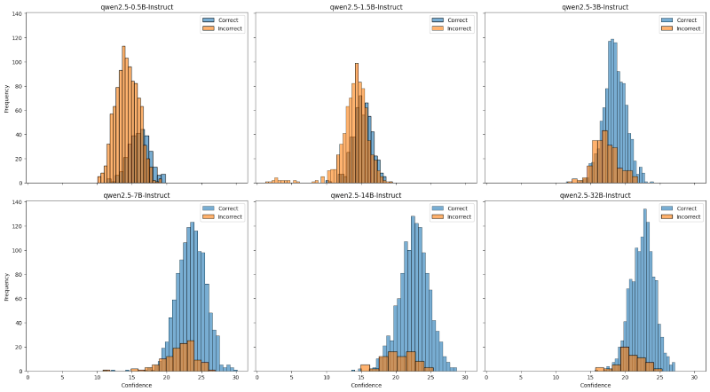
Group Confidence
Grouping tokens and taking confidence at the group level.
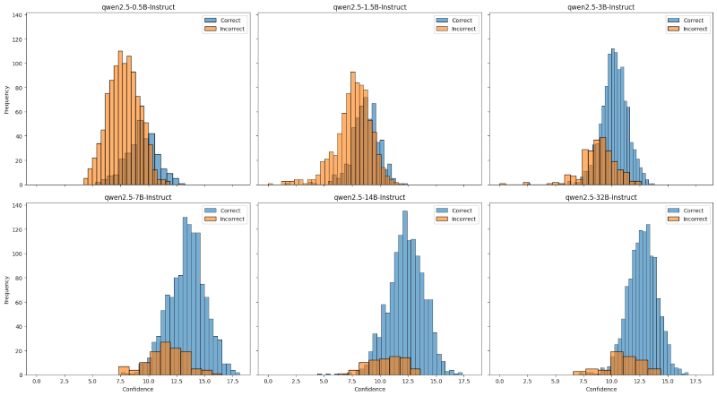
Bottom 10% Confidence
Looking at only the least confident tokens - the idea being that uncertainty in any part of the answer might indicate overall uncertainty.
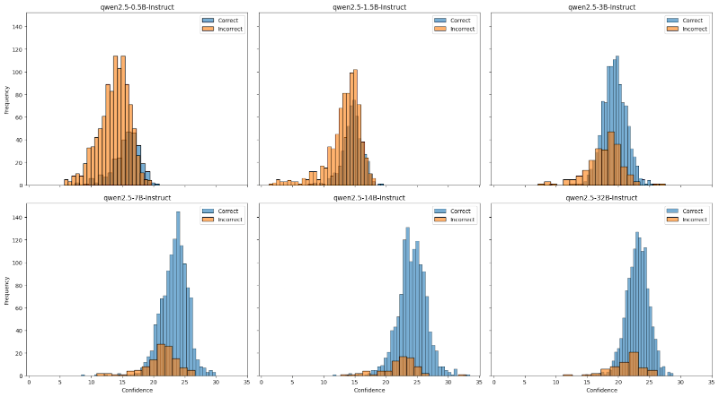
Tail Confidence
Focusing on the final answer tokens since that’s what we care about most.
My Concerns
After looking at these results, I have two major concerns:
The histograms overlap too much. I was hoping to see a clean separation between correct and incorrect answers based on confidence alone. The bottom 10% confidence measure has the best segregation but there’s still significant overlap. This means a router based purely on confidence would have a hard time making good decisions - it would either route too many queries to the expensive model (wasting compute) or miss queries that actually need the bigger model (hurting accuracy).
Different models have different calibrations. Looking across the model sizes, each model has its own confidence distribution. The 0.5B model might output high confidence scores for answers it gets wrong, while the 32B model might be more calibrated. This means we can’t just set a single threshold - we’d need to teach the router to understand each model’s individual calibration quirks.
I’m not giving up on this idea yet but I think the pure confidence-based approach might need to be combined with something else. Maybe training a small classifier on top of the confidence features, or using confidence as just one signal among several. The LLM Routing post discusses some other approaches that might complement this.